Segmentação de clientes no E-commerce

Todos os clientes de uma marca possuem um desejo em comum, afinal isso que faz todos tomarem a mesma decisão de compra.
Mas você já parou pra pensar no quão diferentes esses clientes podem ser?
Alguns produtos atingem nichos mais específicos, por exemplo: marca de skate, cursos de programação ou carros esportivos.
Já outros são extremamente abrangentes, como uma marca de tênis ou de paste de dente.
Mas, em cada um deles, o cliente final é uma pessoa que ficará mais satisfeita a medida que for tratada de forma mais individual.
E, claro, a satisfação do cliente se traduz em maior faturamento para uma empresa a médio e longo prazo.
Além disso, existem dois riscos para uma empresa quando ela vai oferecer um produto:
Oferecer excessivamente para um público que não precisa ou não tem interesse em comprar.
Não oferecer o produto para um público que precisa e estaria disposto a comprar.
No primeiro caso, a empresa pode prejudicar a sua imagem sendo insistente, por exemplo.
Já no segundo caso, ela está perdendo dinheiro e deixando de atender clientes que precisam e gostariam de adquirir seus produtos.
E é exatamente sobre esse dois pontos que a nossa análise vai tratar.
Mais especificamente na venda para clientes que já compraram da empresa.
O nosso case trará dados reais de uma empresa de varejo do Reino Unido durante 1 ano de vendas.
Os clientes serão segmentados de acordo com a técnica RFM, baseada em 3 variáveis:
Há quanto tempo foi a última compra - R (Recency)
Frequência de compras - F (Frequency)
Valor gasto - M (Monetary Value)
O que é o método RFM?
A técnica RFM tem como objetivo principal classificar os clientes, levando em conta os três fatores citados - Tempo da última compra, Frequência e Valor gasto.
Então, o melhor cliente possível é aquele que comprou recentemente, está sempre comprando e faz compras com valores elevados.
Como o RFM pode ser usado para aumentar as vendas de uma empresa?
As empresas usam a técnica para fidelizar ainda mais clientes assíduos da marca, os recompensando com benefícios exclusivos.
Por outro lado, os clientes que já não compram há algum tempo podem ser resgatados com uma campanha de marketing específica. Antes que acabem fidelizando à marca concorrente.
A técnica RFM irá classificar os clientes em relação aos 3 fatores aqui falados. Então, vamos colocar a mão na massa!
Reprodução da análise
O projeto original e os dados utilizados podem ser encontrados clicando aqui.
Bibliotecas que vamos usar na análise
library(data.table)
library(dplyr)
library(ggplot2)
library(tidyr)
library(knitr)Leitura dos dados
Os dados possuem registros de 541.909 compras durante o período de um ano no e-commerce de uma empresa Britânica.
As principais variáveis que vamos utilizar na análise são: id do cliente, data da compra e valor da compra.
df_data <- fread('data_segmentacao.csv')
glimpse(df_data)## Rows: 541,909
## Columns: 8
## $ InvoiceNo <chr> "536365", "536365", "536365", "536365", "536365", "5363...
## $ StockCode <chr> "85123A", "71053", "84406B", "84029G", "84029E", "22752...
## $ Description <chr> "WHITE HANGING HEART T-LIGHT HOLDER", "WHITE METAL LANT...
## $ Quantity <int> 6, 6, 8, 6, 6, 2, 6, 6, 6, 32, 6, 6, 8, 6, 6, 3, 2, 3, ...
## $ InvoiceDate <chr> "12/1/2010 8:26", "12/1/2010 8:26", "12/1/2010 8:26", "...
## $ UnitPrice <dbl> 2.55, 3.39, 2.75, 3.39, 3.39, 7.65, 4.25, 1.85, 1.85, 1...
## $ CustomerID <int> 17850, 17850, 17850, 17850, 17850, 17850, 17850, 17850,...
## $ Country <chr> "United Kingdom", "United Kingdom", "United Kingdom", "...Limpeza dos dados
Caso tenha valores discrepantes que não façam sentido, iremos substituir por NA (not available).
df_data <- df_data %>%
mutate(Quantity = replace(Quantity, Quantity<=0, NA),
UnitPrice = replace(UnitPrice, UnitPrice<=0, NA))
df_data <- df_data %>%
drop_na()Ajustes nas variáveis
Ajustando as variáveis para fazer a nossa análise.
df_data <- df_data %>%
mutate(InvoiceNo=as.factor(InvoiceNo), StockCode=as.factor(StockCode),
InvoiceDate=as.Date(InvoiceDate, '%m/%d/%Y %H:%M'), CustomerID=as.factor(CustomerID),
Country=as.factor(Country))
df_data <- df_data %>%
mutate(total_dolar = Quantity*UnitPrice)glimpse(df_data)## Rows: 397,884
## Columns: 9
## $ InvoiceNo <fct> 536365, 536365, 536365, 536365, 536365, 536365, 536365,...
## $ StockCode <fct> 85123A, 71053, 84406B, 84029G, 84029E, 22752, 21730, 22...
## $ Description <chr> "WHITE HANGING HEART T-LIGHT HOLDER", "WHITE METAL LANT...
## $ Quantity <int> 6, 6, 8, 6, 6, 2, 6, 6, 6, 32, 6, 6, 8, 6, 6, 3, 2, 3, ...
## $ InvoiceDate <date> 2010-12-01, 2010-12-01, 2010-12-01, 2010-12-01, 2010-1...
## $ UnitPrice <dbl> 2.55, 3.39, 2.75, 3.39, 3.39, 7.65, 4.25, 1.85, 1.85, 1...
## $ CustomerID <fct> 17850, 17850, 17850, 17850, 17850, 17850, 17850, 17850,...
## $ Country <fct> United Kingdom, United Kingdom, United Kingdom, United ...
## $ total_dolar <dbl> 15.30, 20.34, 22.00, 20.34, 20.34, 15.30, 25.50, 11.10,...Calcular: Recência, Frequencia e Valor gasto
Primeiramente, vamos separar os cálculos pelo ID do cliente, já que toda a análise gira em torno do próprio consumidor.
A recência será calculada como a distância entre o dia mais recente do banco de dados e a última compra do cliente. Neste caso, o banco de dados mostra as compras até 1º de janeiro de 2012. Então a recência será o valor de dias que se passaram da última compra do cliente até o dia 01/01/2012.
A frequência é calculada pelo número de notas fiscais geradas para cada cliente.
O valor gasto é calculado pelo total gasto em todas as compras, dividido pela quantidade de compras. Ou seja, é o gasto médio do consumidor.
df_RFM <- df_data %>%
group_by(CustomerID) %>%
summarise(recency=as.numeric(as.Date("2012-01-01")-max(InvoiceDate)),
frequenci=n_distinct(InvoiceNo), monetary= sum(total_dolar)/n_distinct(InvoiceNo)) O resultado calculado acima mostra o valor de cada uma das três variáveis para cada cliente.
summary(df_RFM)## CustomerID recency frequenci monetary
## 12346 : 1 Min. : 23.0 Min. : 1.000 Min. : 3.45
## 12347 : 1 1st Qu.: 40.0 1st Qu.: 1.000 1st Qu.: 178.62
## 12348 : 1 Median : 73.0 Median : 2.000 Median : 293.90
## 12349 : 1 Mean :115.1 Mean : 4.272 Mean : 419.17
## 12350 : 1 3rd Qu.:164.8 3rd Qu.: 5.000 3rd Qu.: 430.11
## 12352 : 1 Max. :396.0 Max. :209.000 Max. :84236.25
## (Other):4332kable(head(df_RFM))| CustomerID | recency | frequenci | monetary |
|---|---|---|---|
| 12346 | 348 | 1 | 77183.6000 |
| 12347 | 25 | 7 | 615.7143 |
| 12348 | 98 | 4 | 449.3100 |
| 12349 | 41 | 1 | 1757.5500 |
| 12350 | 333 | 1 | 334.4000 |
| 12352 | 59 | 8 | 313.2550 |
Histogramas - Gráficos de frequência para cada variável
Os histogramas serão criados com o objetivo de avaliar a distribuição de cada variável e suas semelhanças com a distribuição normal.
hist(df_RFM$recency)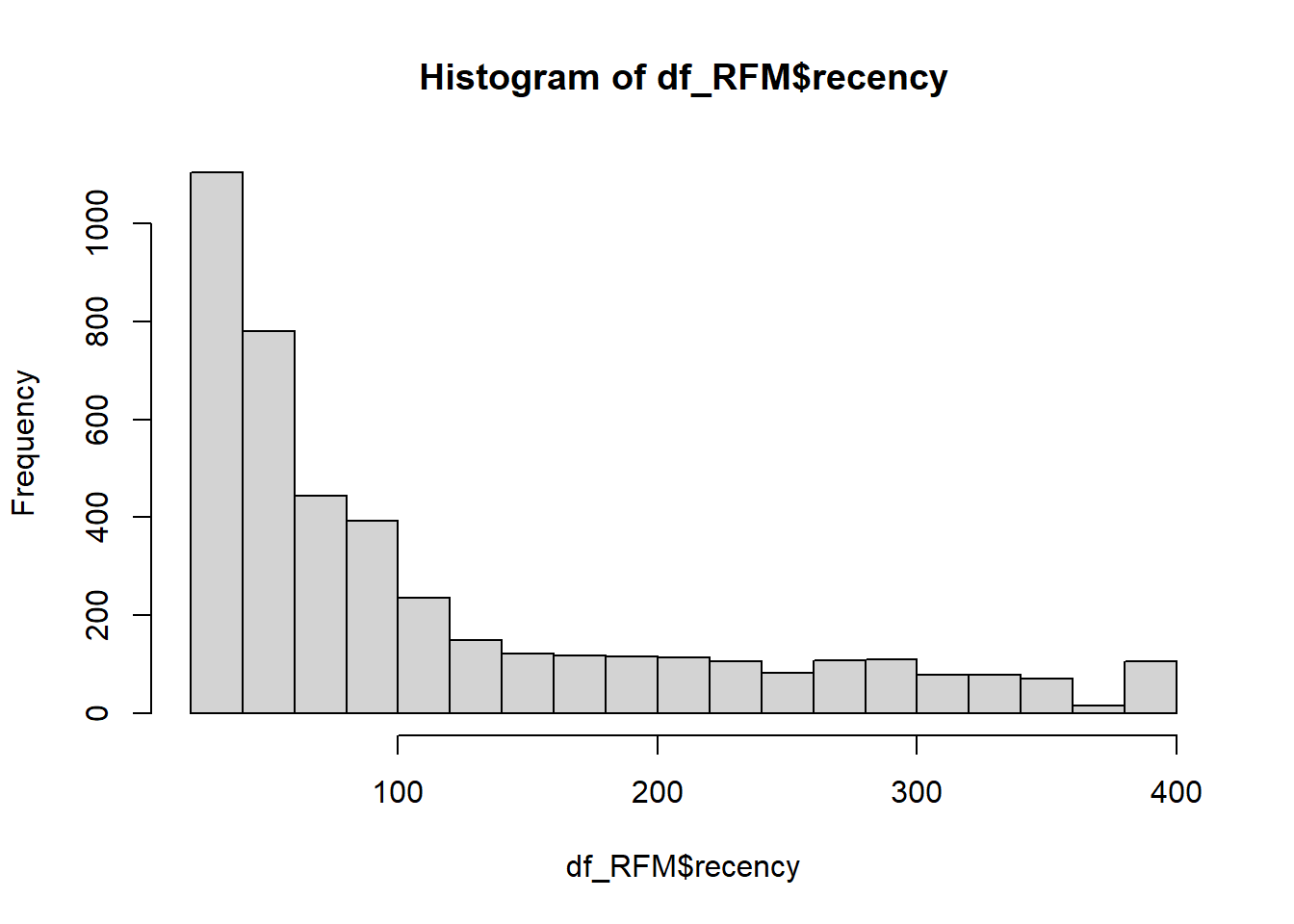
hist(df_RFM$frequenci, breaks = 50)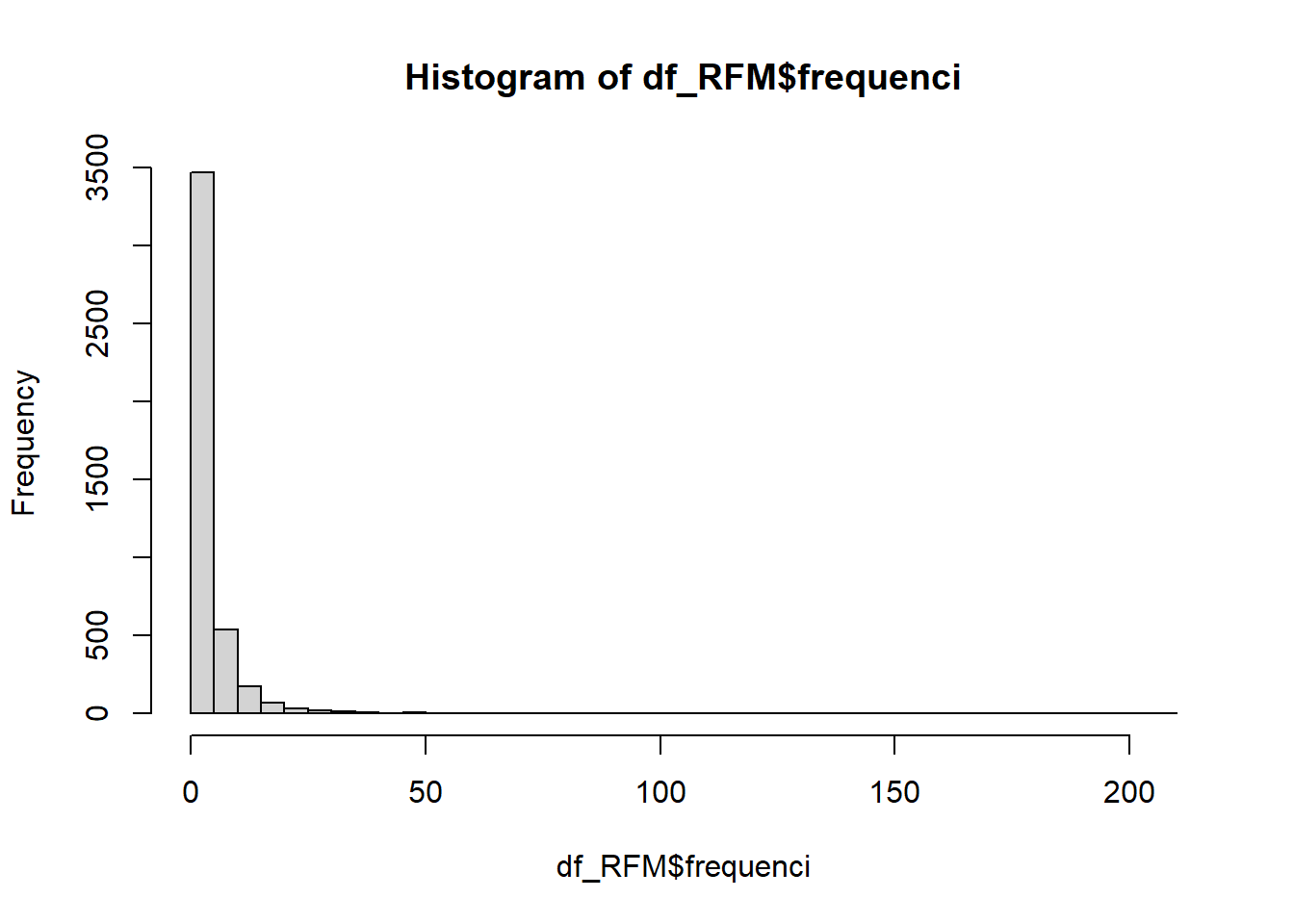
hist(df_RFM$monetary, breaks = 50)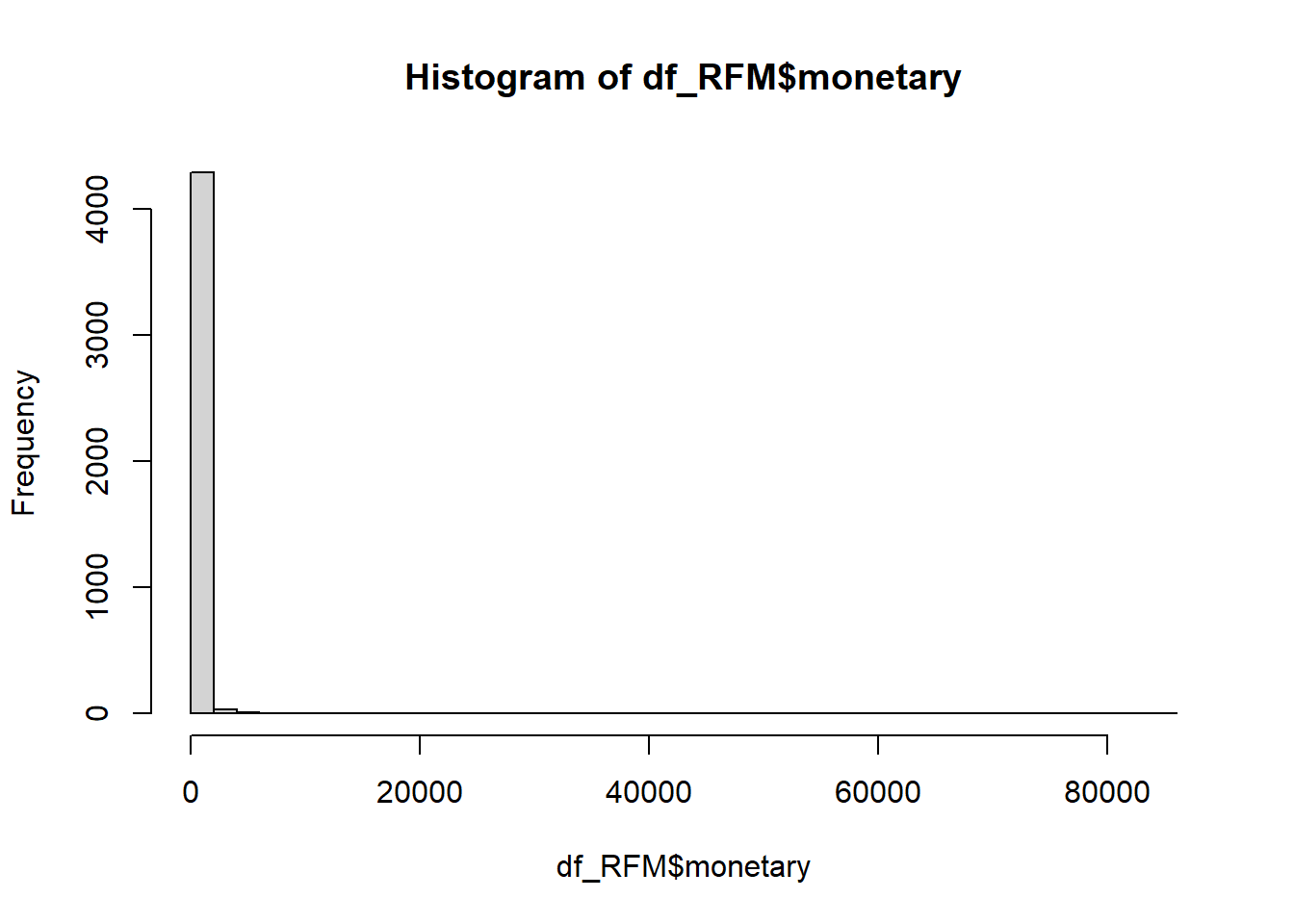
Reduzindo a assimetria dos dados transformando com a escala log
Iremos transformar os valores da variável referente ao gasto usando a escala log.
Essa transformação é recomendada para reduzir a assimetria dos dados que iremos usar na análise de agrupamentos.
df_RFM$monetary <- log(df_RFM$monetary)
hist(df_RFM$monetary)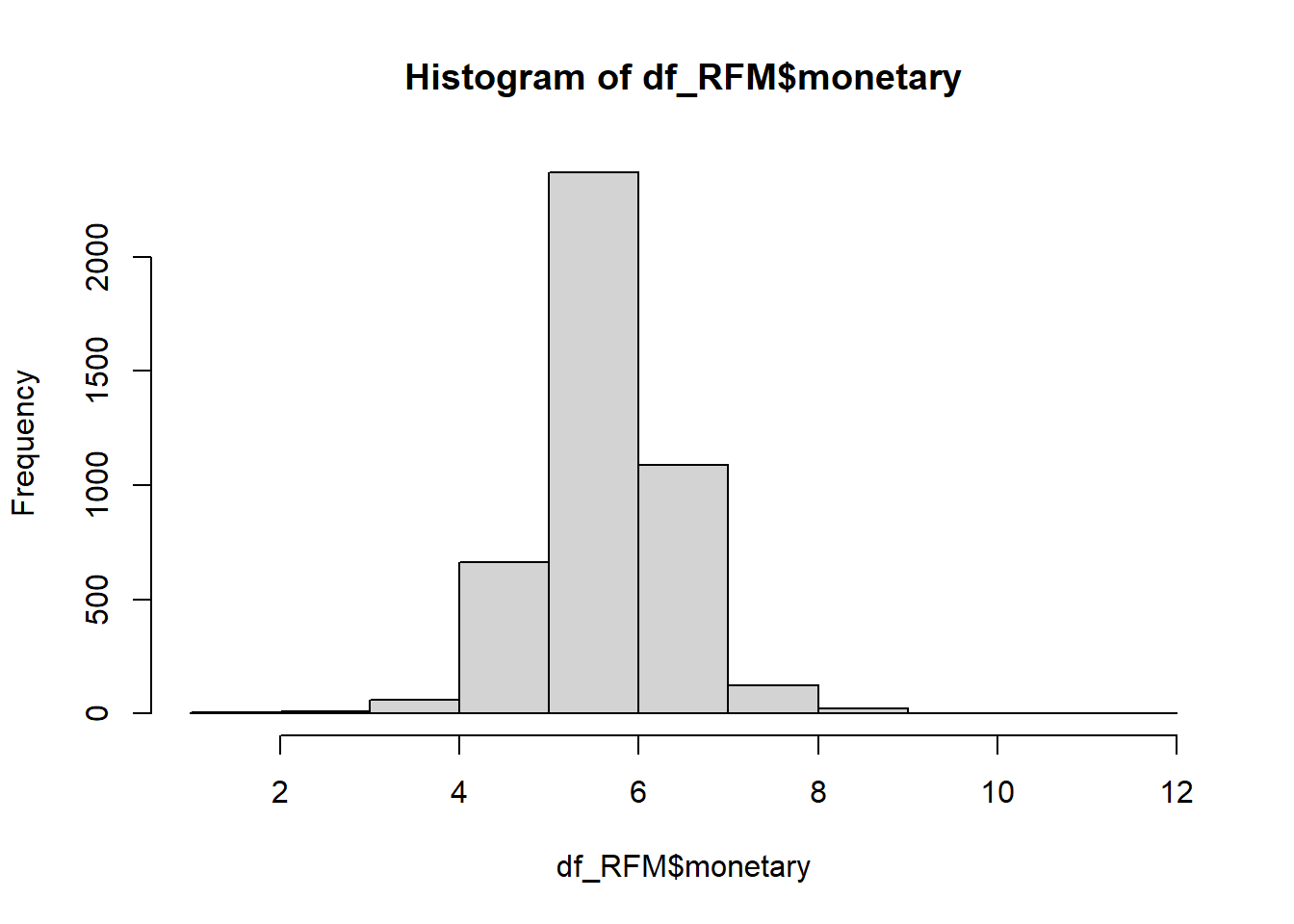
Agrupamento
Nesse passo vamos agrupar os consumidores de acordo com as 3 variáveis em questão.
Antes de distribuir os grupos, calcula-se uma distância entre os consumidores baseada nas 3 variáveis em análise.
Consumidores parecidos terão uma distância pequena entre eles, enquanto consumidores com padrões diferentes terão uma distância grande entre eles.
# Atribuir o ID de cada usuário para o nome da linha
df_RFM2 <- df_RFM
row.names(df_RFM2) <- df_RFM2$CustomerID
df_RFM2$CustomerID <- NULL
# Padronizar cada uma das variáveis (normal padrão com média 0 e variância 1)
df_RFM2 <- scale(df_RFM2)
summary(df_RFM2)## recency frequenci monetary
## Min. :-0.9205 Min. :-0.42505 Min. :-5.8832
## 1st Qu.:-0.7505 1st Qu.:-0.42505 1st Qu.:-0.6153
## Median :-0.4205 Median :-0.29514 Median : 0.0493
## Mean : 0.0000 Mean : 0.00000 Mean : 0.0000
## 3rd Qu.: 0.4968 3rd Qu.: 0.09457 3rd Qu.: 0.5576
## Max. : 2.8091 Max. :26.59496 Max. : 7.6012#Cálculo da Matriz de Distância entre os consumidores
matriz_distancia <- dist(df_RFM2)
#Cálculo dos grupos
grupos <- hclust(matriz_distancia, method = 'ward.D2')Gráfico
O dendograma é um gráfico muito utilizado para definir pontos de corte em uma análise de agrupamentos. É um método visual, porém muito importante.
O parte superior de um dendograma mostra todos os elementos (consumidores) em apenas dois grupos. A parte inferior do Dendograma representa todos os elementos como um grupo, ou seja, cada consumidor seria um grupo.
Nenhum dos extremos é interessante em nossa análise, então cabe ao especialista analisar quando há um grande salto de distância entre os nós de divisão dos grupos e aliar isso a um número de grupos próximo do desejado/viável.
plot(grupos)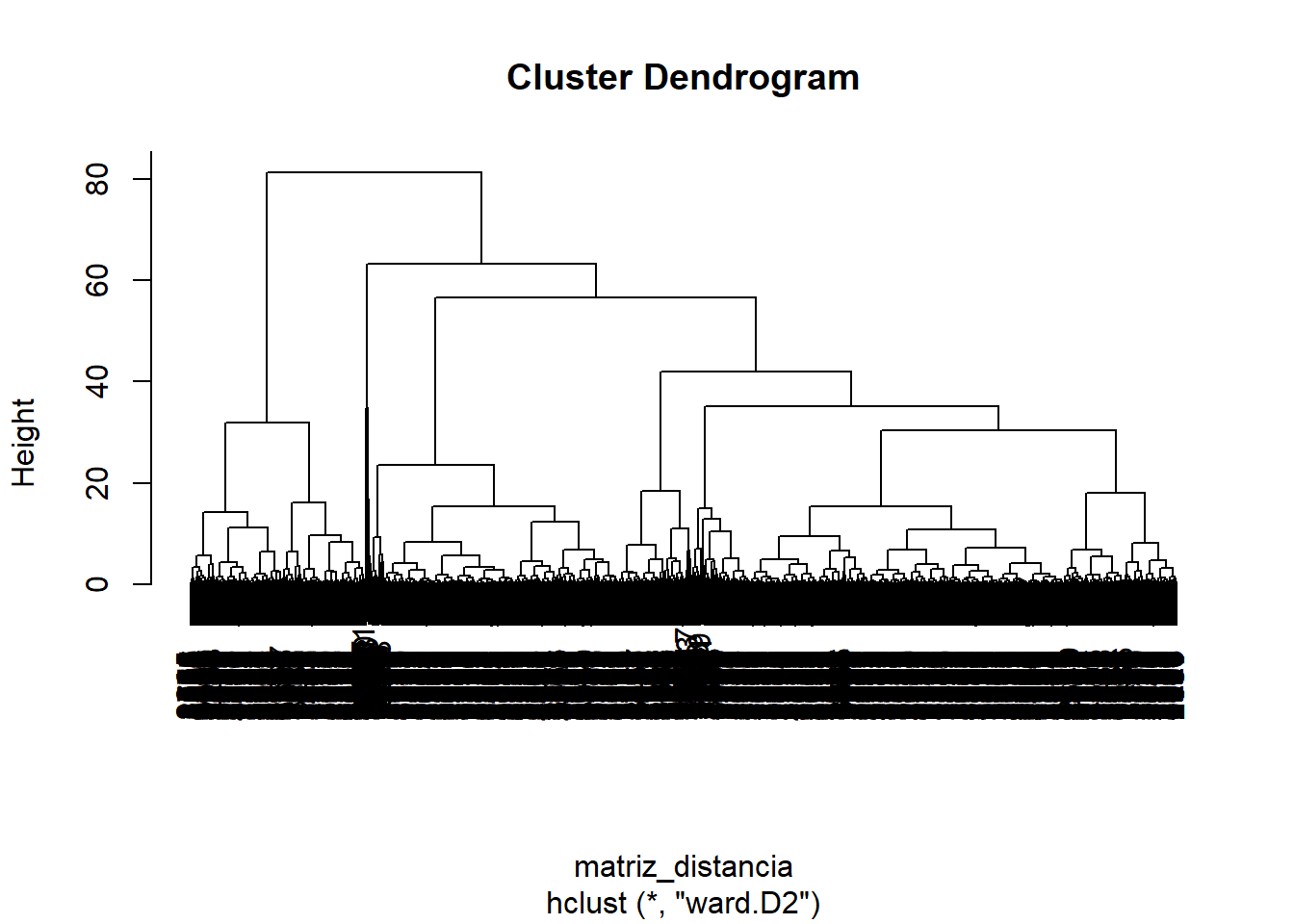
Nesse exemplo, foi definido que o número ideal de grupos é 6.
members <- cutree(grupos,k = 6) #atribuir o grupo a cada consumidor
members[1:5] ## [1] 1 2 2 1 3table(members) #quantidade de consumidores em cada grupo## members
## 1 2 3 4 5 6
## 255 1878 772 1092 319 22Média das variáveis para cada um dos grupos
aggregate(df_RFM[,2:4], by=list(members), mean)## Group.1 recency frequenci monetary
## 1 1 64.56078 5.729412 7.148281
## 2 2 90.12886 3.185304 5.944782
## 3 3 293.65674 1.396373 5.320760
## 4 4 68.29304 2.924908 4.974036
## 5 5 36.06897 16.028213 5.711702
## 6 6 28.09091 77.454545 6.601579Podemos perceber que o grupo 6 compra com uma frequência muito superior quando comparados aos outros grupos. Além disso, é o grupo que fez compras mais recentemente.
Para esse grupo, imagino haver duas hipóteses:
- O grupo comporta os clientes mais fiéis à marca.
- São clientes atacadistas, possíveis revendedores dos produtos do e-commerce analisado.
Obviamente é necessário uma análise mais aprofundada para saber quem realmente são esses clientes e quais o tratamento adequado para esse grupo. Essa análise poderia ser feita com a posse completa dos dados das vendas.
Já o grupo 3 contém clientes que demandarão um esforço maior da empresa para que se tornem fiéis, afinal já não compram há muito tempo (valor alto para “recência”) e compraram, em média, uma única vez.