Quem são os Cientistas de Dados do Brasil?
A maior comunidade de Cientistas de dados do Brasil realizou uma pesquisa com 1.765 membros para conhecer mais sobre eles.
É a maior pesquisa brasileira deste segmento e trouxe muito valor para a área.
Foram aplicadas 36 perguntas. Desde perguntas básicas sobre o perfil de cada um até perguntas mais específicas da área, como:
área de atuação, área de formação, tempo de experiência, ferramentas e linguagens utilizadas no trabalho e até a faixa salarial.
Qual é o salário médio da categoria e quais variáveis estão muito relacionadas ao seu valor?
Qual é a linguagem de programação mais utilizada pelos Cientistas de dados?
Qual é a linguagem de programação utilizada pelos Cientistas de dados que ganham mais $$$??
Para responder essas e várias outras perguntas, analisei as principais informações da pesquisa.
Você conhece o gráfico MAPTREE?
Vou mostrar esse gráfico que é muito pouco utilizado, mas é ideal em alguns casos. Ele te ajudará muito na exploração das informações. Leia até o final do post para não perder.
O banco de dados completo está disponível em:
kaggle.com/datahackers/pesquisa-data-hackers-2019
Bibliotecas usadas na análise
library(readr)
library(treemap)
# devtools::install_github("timelyportfolio/d3treeR")
library(d3treeR)
library(knitr)
library(rpart)
library(rattle)
library(rpart.plot)
library(RColorBrewer)
library(shiny)
library(plyr)
library(dplyr)
library(magrittr)
library(readr)
library(FSelector)
library(treemap)Leitura dos dados e seleção das perguntas que iremos trabalhar aqui.
datahackers <- read_csv("datahackers.csv")
datahackers<-select(datahackers,`('P1', 'age')`,`('P2', 'gender')`,`('P5', 'living_state')`,`('P8', 'degreee_level')`,
`('P10', 'job_situation')`,`('P12', 'workers_number')`,`('P13', 'manager')`,`('P16', 'salary_range')`,
`('P17', 'time_experience_data_science')`,`('P19', 'is_data_science_professional')`,`('P21', 'sql_')`,`('P21', 'r')`,
`('P21', 'python')`,`('D3', 'anonymized_degree_area')`,
`('D4', 'anonymized_market_sector')`,`('D6', 'anonymized_role')`)Transformando a variável de idade em uma variável categórica
labs <- c(paste(c(0,19,25,30,35,40,45,50),c(18,24,29,34,39,44,49,54),
sep = "-"), paste(55, "+", sep = ""))
datahackers$age<- cut(datahackers$`('P1', 'age')`, breaks = c(0,19,25,30,35,40,45,50,55,Inf), labels = labs, right = FALSE)Alterando os nomes das perguntas
names(datahackers)<-c("Idade_raw","Genero","Estado","Escolaridade","Empregado","No. funcionarios empresa","Gerente","Faixa salarial",
"Tempo de experiencia em DS","Cientista de dados","SQL","R","python","Area de formacao","Area de atuacao","Cargo","Idade")Os respondentes informaram apenas a faixa salarial, então vamos criar uma nova variável com o valor médio dos salários de cada faixa. Assim poderemos fazer cálculos com essa nova variável.
datahackers$salario<-as.numeric(mapvalues(datahackers$`Faixa salarial`,
from=c("Menos de R$ 1.000/mês","de R$ 1.001/mês a R$ 2.000/mês","de R$ 2.001/mês a R$ 3000/mês",
"de R$ 3.001/mês a R$ 4.000/mês","de R$ 4.001/mês a R$ 6.000/mês","de R$ 6.001/mês a R$ 8.000/mês",
"de R$ 8.001/mês a R$ 12.000/mês","de R$ 12.001/mês a R$ 16.000/mês","de R$ 16.001/mês a R$ 20.000/mês",
"de R$ 20.001/mês a R$ 25.000/mês","Acima de R$ 25.001/mês",NA),
to=c(500,1500,2500,3500,5000,7000,10000,14000,18000,22500,30000,NA)))Qual é a linguagem de programação mais utilizada?
# LINGUAGENS DE PROGRAMAÇÃO
# R
freq_R<-data.frame(table(datahackers$R)) %>% filter(Var1==1)%>% select(Freq)
freq_SQL<-data.frame(table(datahackers$SQL)) %>% filter(Var1==1)%>% select(Freq)
freq_python<-data.frame(table(datahackers$python)) %>% filter(Var1==1)%>% select(Freq)
linguagem<-data.frame(lang=c("R","SQL","python"),Freq=rbind(freq_R,freq_SQL,freq_python))
kable(arrange(linguagem,-Freq))| lang | Freq |
|---|---|
| python | 784 |
| SQL | 714 |
| R | 318 |
A linguagem de programação mais utilizada pelos membros da comunidade é o Python. Sabemos que a linguagem de programação escolhida é muito relacionada a origem do programador. Então mais a frente veremos a origem/área de formação dos respondentes da pesquisa.
Quais programadores ganham mais? R ou Python?
R_salario <- datahackers %>%
group_by(R) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario) %>%
filter(R==1) %>%
select(media_salario)
SQL_salario <- datahackers %>%
group_by(SQL) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario) %>%
filter(SQL==1) %>%
select(media_salario)
python_salario <- datahackers %>%
group_by(python) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario) %>%
filter(python==1) %>%
select(media_salario)
linguagem_salario<-data.frame(lang=c("R","SQL","python"),Freq=rbind(R_salario,SQL_salario,python_salario))
kable(arrange(linguagem_salario,-media_salario))| lang | media_salario |
|---|---|
| R | 7879 |
| python | 7076 |
| SQL | 7069 |
Apesar de serem maioria, os programadores da linguagem python ganham menos que os programadores da linguagem R. Isso já havia sido identificado em outras pesquisas, inclusive mundiais. Veja em:
businessinsider.com/the-top-coding-languages-with-the-highest-salary-2020-4
A área de formação do programador determina qual a linguagem ele irá utilizar?
#R
datahackers_R<-filter(datahackers,R==1)
datahackers_R<-aggregate(R ~`Area de formacao`,datahackers_R,length)
#SQL
datahackers_sql<-filter(datahackers,SQL==1)
datahackers_sql<-aggregate(SQL ~`Area de formacao`,datahackers_sql,length)
#Python
datahackers_py<-filter(datahackers,python==1)
datahackers_py<-aggregate(python ~`Area de formacao`,datahackers_py,length)
area_linguagem<-join(datahackers_R,datahackers_sql)
area_linguagem<-join(area_linguagem,datahackers_py)
area_linguagem$R<-paste0(round(area_linguagem$R*100/sum(area_linguagem$R),0),"%")
area_linguagem$SQL<-paste0(round(area_linguagem$SQL*100/sum(area_linguagem$SQL),0),"%")
area_linguagem$python<-paste0(round(area_linguagem$python*100/sum(area_linguagem$python),0),"%")
kable(area_linguagem)| Area de formacao | R | SQL | python |
|---|---|---|---|
| Ciências Sociais | 2% | 1% | 1% |
| Computação / Engenharia de Software / Sistemas de Informação | 39% | 58% | 57% |
| Economia/ Administração / Contabilidade / Finanças | 12% | 10% | 9% |
| Estatística/ Matemática / Matemática Computacional | 19% | 8% | 8% |
| Marketing / Publicidade / Comunicação / Jornalismo | 2% | 1% | 2% |
| Outras | 6% | 4% | 4% |
| Outras Engenharias | 18% | 16% | 17% |
| Química / Física | 1% | 2% | 2% |
Obviamente, podemos ter um cientista da computação que prefere a linguagem R e um estatístico que prefira python. Mas há uma tendência pelo contrário.
Profissionais com origens na área computacional tem grande tendência em usar o python. Isso por ser uma linguagem genérica, que não é específica para Data Science. Ou seja, provavelmente já era uma linguagem que usavam antes de entrar para a área de Ciência de dados.
Para as demais áreas, há um predomínio de uso da linguagem R, já que ela é mais fácil de ser aprendida e é específica para a Ciência de Dados.
A linguagem SQL é totalmente complementar às linguagens R e Python, sendo usada em conjunto com uma delas.
#### sabem SQL e R ou Python
# R e SQL
# % de quem sabe SQL dentre quem sabe R
datahackers_R<-filter(datahackers,R==1)
cat("Entre os entrevistados que usam a linguagem R, ",round(sum(datahackers_R$SQL)*100/sum(datahackers_R$R),1),"% também usam SQL.",sep="")## Entre os entrevistados que usam a linguagem R, 77.4% também usam SQL.# Python e SQL
# % de quem sabe SQL dentre quem sabe Python
datahackers_py<-filter(datahackers,python==1)
cat("Entre os entrevistados que usam a linguagem Python, ",round(sum(datahackers_py$SQL)*100/sum(datahackers_py$python),1),"% também usam SQL.",sep="")## Entre os entrevistados que usam a linguagem Python, 77.9% também usam SQL.Qual a idade dos Cientistas de Dados?
# Idade
hist(datahackers$Idade_raw,xlab="Idade",ylab = "Frequência",main="Histograma de idade")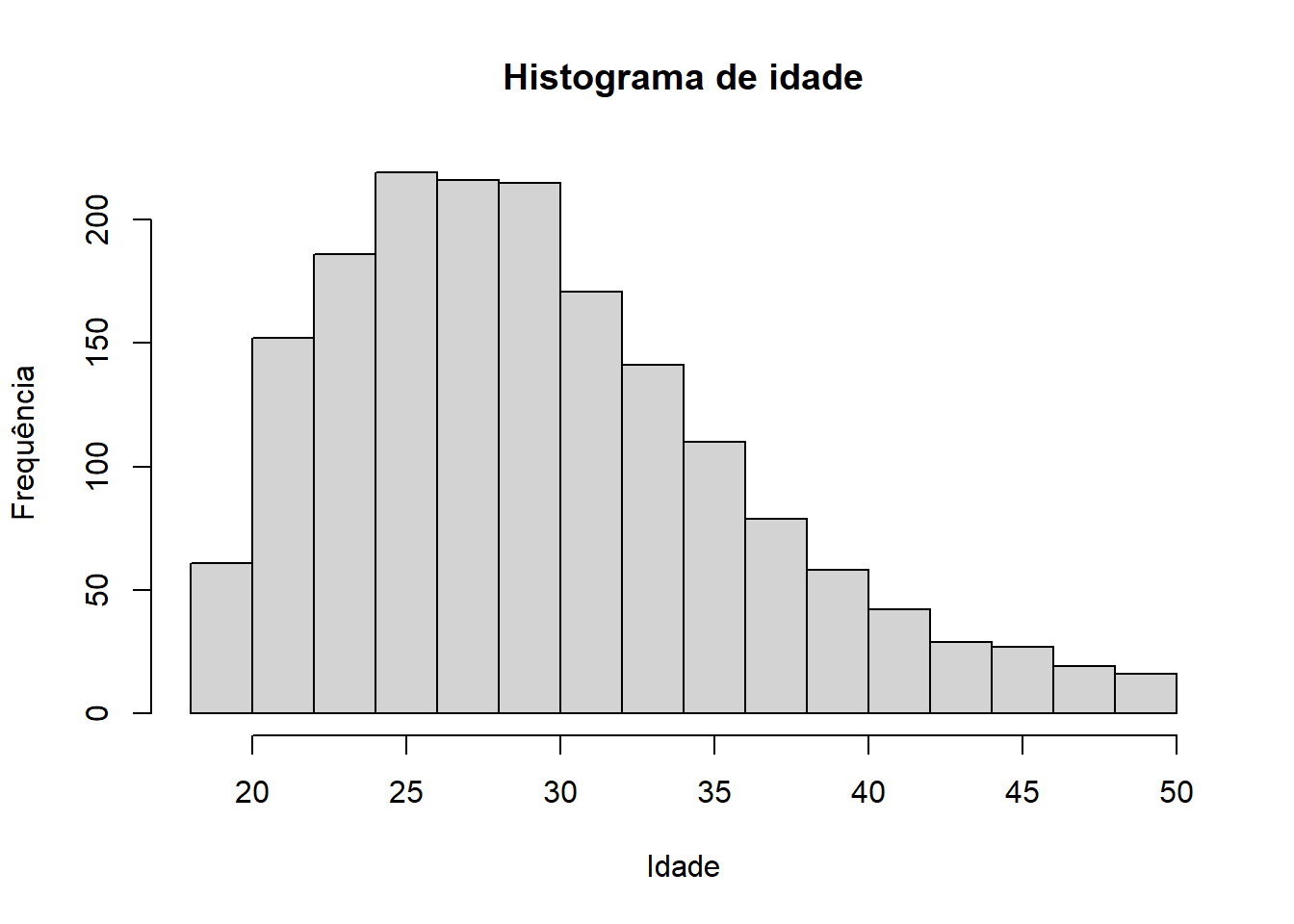
Qual o nível de escolaridade?
# Escolaridade
Escolaridade_freq<-data.frame(table(datahackers$Escolaridade))
kable(arrange(Escolaridade_freq,-Freq))| Var1 | Freq |
|---|---|
| Graduação/Bacharelado | 578 |
| Pós-graduação | 527 |
| Estudante de Graduação | 374 |
| Mestrado | 201 |
| Doutorado ou Phd | 50 |
| Não tenho graduação formal | 34 |
| Prefiro não informar | 1 |
Nível de escolaridade vs Salário
kable(datahackers %>%
group_by(Escolaridade) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario))| Escolaridade | media_salario |
|---|---|
| Doutorado ou Phd | 12632 |
| Mestrado | 9061 |
| Não tenho graduação formal | 7734 |
| Pós-graduação | 7622 |
| Graduação/Bacharelado | 5759 |
| Estudante de Graduação | 2712 |
| Prefiro não informar | 2500 |
Onde eles trabalham?
Os estados com poucas respostas foram omitidos pelos organizadores da pesquisa para garantir a privacidade dos respondentes.
# Localização
#estado
Estado_freq<-data.frame(table(datahackers$Estado))
kable(arrange(Estado_freq,-Freq))| Var1 | Freq |
|---|---|
| São Paulo (SP) | 669 |
| Minas Gerais (MG) | 316 |
| Rio de Janeiro (RJ) | 147 |
| Paraná (PR) | 117 |
| Santa Catarina (SC) | 83 |
| Rio Grande do Sul (RS) | 69 |
| Espírito Santo (ES) | 27 |
Qual a média salarial de cada estado?
kable(datahackers %>%
group_by(Estado) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario))| Estado | media_salario |
|---|---|
| São Paulo (SP) | 7088 |
| NA | 6473 |
| Rio de Janeiro (RJ) | 6339 |
| Espírito Santo (ES) | 5841 |
| Minas Gerais (MG) | 5448 |
| Paraná (PR) | 5412 |
| Rio Grande do Sul (RS) | 5288 |
| Santa Catarina (SC) | 4880 |
Qual o tipo de emprego mais comum?
# Tipo de emprego
Empregado_freq<-data.frame(table(datahackers$Empregado))
kable(arrange(Empregado_freq,-Freq))| Var1 | Freq |
|---|---|
| Empregado (CTL) | 1073 |
| Empreendedor ou Empregado (CNPJ) | 234 |
| Estagiário | 131 |
| Somente Estudante (graduação) | 85 |
| Desempregado, buscando recolocação | 69 |
| Servidor Público | 60 |
| Trabalho na área Acadêmica/Pesquisador | 45 |
| Somente Estudante (pós-graduação) | 36 |
| Freelancer | 23 |
| Prefiro não dizer | 6 |
| Desempregado e não estou buscando recolocação | 3 |
Onde trabalham os cientistas de dados que, em média, ganham mais?
kable(datahackers %>%
group_by(Empregado) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario))| Empregado | media_salario |
|---|---|
| Servidor Público | 8575 |
| Empreendedor ou Empregado (CNPJ) | 8479 |
| Prefiro não dizer | 6917 |
| Empregado (CTL) | 6368 |
| Freelancer | 4000 |
| Estagiário | 1302 |
| Desempregado e não estou buscando recolocação | NaN |
| Desempregado, buscando recolocação | NaN |
| Somente Estudante (graduação) | NaN |
| Somente Estudante (pós-graduação) | NaN |
| Trabalho na área Acadêmica/Pesquisador | NaN |
Quantos tem cargo de gerência?
# É gerente?
Gerente_freq<-data.frame(table(datahackers$Gerente))
kable(arrange(Gerente_freq,-Freq))| Var1 | Freq |
|---|---|
| 0 | 1222 |
| 1 | 305 |
Qual o salário médio dos gerentes e não-gerentes?
kable(datahackers %>%
group_by(Gerente) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario))| Gerente | media_salario |
|---|---|
| 1 | 9503 |
| 0 | 5513 |
| NA | NaN |
Qual o tempo de experiência dos membros da comunidade?
# Tempo de experiência
tempo_freq<-data.frame(table(datahackers$`Tempo de experiencia em DS`))
kable(arrange(tempo_freq,-Freq))| Var1 | Freq |
|---|---|
| Menos de 1 ano | 445 |
| de 1 a 2 anos | 343 |
| de 2 a 3 anos | 244 |
| Não tenho experiência na área de dados | 221 |
| de 4 a 5 anos | 186 |
| de 6 a 10 anos | 179 |
| Mais de 10 anos | 147 |
Relação entre tempo de experiência e salário.
kable(datahackers %>%
group_by(`Tempo de experiencia em DS`) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario))| Tempo de experiencia em DS | media_salario |
|---|---|
| Mais de 10 anos | 10827 |
| de 6 a 10 anos | 9555 |
| de 4 a 5 anos | 8494 |
| de 2 a 3 anos | 6284 |
| de 1 a 2 anos | 5106 |
| Não tenho experiência na área de dados | 4623 |
| Menos de 1 ano | 3929 |
Entre os membros da comunidade, quantos se consideram cientistas de dados?
# É cientista de dados?
cientista_freq<-data.frame(table(datahackers$`Cientista de dados`))
kable(arrange(cientista_freq,-Freq))| Var1 | Freq |
|---|---|
| 1 | 915 |
| 0 | 850 |
Entre os membros da comunidade Data Hackers, 915 respondentes afirmaram desempenhar funções típicas de um Cientista de Dados.
Qual a diferença de salário entre os membros cientistas de dados e os que não são?
kable(datahackers %>%
group_by(`Cientista de dados`) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario))| Cientista de dados | media_salario |
|---|---|
| 1 | 6986 |
| 0 | 5576 |
Qual a frequência dos membros por área de formação?
# Área de formação
formacao_freq<-data.frame(table(datahackers$`Area de formacao`))
kable(arrange(formacao_freq,-Freq))| Var1 | Freq |
|---|---|
| Computação / Engenharia de Software / Sistemas de Informação | 1013 |
| Outras Engenharias | 247 |
| Economia/ Administração / Contabilidade / Finanças | 174 |
| Estatística/ Matemática / Matemática Computacional | 104 |
| Outras | 92 |
| Marketing / Publicidade / Comunicação / Jornalismo | 47 |
| Química / Física | 28 |
| Ciências Sociais | 25 |
Variação do salário por área de formação.
kable(datahackers %>%
group_by(`Area de formacao`) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario))| Area de formacao | media_salario |
|---|---|
| Química / Física | 8974 |
| NA | 7576 |
| Estatística/ Matemática / Matemática Computacional | 7543 |
| Marketing / Publicidade / Comunicação / Jornalismo | 6630 |
| Economia/ Administração / Contabilidade / Finanças | 6267 |
| Outras Engenharias | 6227 |
| Computação / Engenharia de Software / Sistemas de Informação | 6206 |
| Outras | 5475 |
| Ciências Sociais | 5056 |
Em quais cargos eles estão alocados?
# Cargo
cargo_freq<-data.frame(table(datahackers$Cargo))
kable(arrange(cargo_freq,-Freq))| Var1 | Freq |
|---|---|
| Desenvolvedor ou Engenheiro de Software | 225 |
| Outras | 220 |
| Data Scientist/Cientista de Dados | 167 |
| Data Analyst/Analista de Dados | 163 |
| Business Intelligence/Analista de BI | 150 |
| Data Engineer/Engenheiro de Dados | 130 |
| Business Analyst/Analista de Negócios | 72 |
| Analista de Inteligência de Mercado | 29 |
| Engenheiro | 26 |
| Analista de Marketing | 19 |
| Engenheiro de Machine Learning | 15 |
| DBA/Administrador de Banco de Dados | 14 |
| Estatístico | 11 |
| Economista | 10 |
Diferença salarial pelos cargos:
kable(datahackers %>%
group_by(Cargo) %>%
summarise(media_salario = round(mean(salario,na.rm=T),0)) %>%
arrange(-media_salario))| Cargo | media_salario |
|---|---|
| NA | 9513 |
| Data Engineer/Engenheiro de Dados | 8227 |
| Engenheiro de Machine Learning | 8000 |
| Engenheiro | 7615 |
| Data Scientist/Cientista de Dados | 6784 |
| Estatístico | 6591 |
| Business Analyst/Analista de Negócios | 5646 |
| Desenvolvedor ou Engenheiro de Software | 5109 |
| Data Analyst/Analista de Dados | 5021 |
| Business Intelligence/Analista de BI | 4870 |
| Outras | 4723 |
| DBA/Administrador de Banco de Dados | 4571 |
| Economista | 4150 |
| Analista de Inteligência de Mercado | 3759 |
| Analista de Marketing | 3079 |
Map Tree
O gráfico de hierarquia das variáveis mais importantes para definir o Salário do profissional.
O Map Tree não está entre os gráficos mais utilizados. Talvez porque precise ser dinâmico para ser mais útil e informativo.
Porém, considero que é um dos gráficos mais interessantes quando você trabalha com variáveis prioritariamente categóricas e precisar demonstar a importância de suas variáveis para prever a variável resposta.
A nossa variável de interesse é o salário mensal dos respondentes.
names(datahackers)<-gsub(" ",".",names(datahackers))
datahackers<-select(datahackers,Faixa.salarial,Genero,Estado,Escolaridade,
Empregado,No..funcionarios.empresa,Gerente,
Tempo.de.experiencia.em.DS,Cientista.de.dados,SQL,R,
python,Area.de.formacao,Area.de.atuacao,Cargo,
Idade)Optei por excluir algumas variáveis nessa análise gráfica:
Empregado -> Saber se a pessoa está empregada ou não é a variável mais importante para prever a média salarial, porém não faz muito sentido prever o salário de pessoas que não estão trabalhando.
Escolaridade e Idade -> Foram excluídas porque apresentaram uma relação muito grande com a variável Tempo de experiência, então optei por deixar apenas esta.
variaveis<-information.gain(formula(datahackers), datahackers)
variaveis$val<-row.names(variaveis)
variaveis <- arrange(variaveis,-attr_importance)
variaveis<-variaveis[!variaveis$val%in%c('Empregado',"Escolaridade","Idade"),]
datahackers_sel<-select(datahackers,variaveis$val[1:3],"Faixa.salarial")
kable(variaveis[1:3,])| attr_importance | val | |
|---|---|---|
| Tempo.de.experiencia.em.DS | 0.1732980 | Tempo.de.experiencia.em.DS |
| Cargo | 0.1335318 | Cargo |
| Area.de.atuacao | 0.0798440 | Area.de.atuacao |
datahackers_sel<-aggregate(list(count=rep(1,nrow(datahackers_sel))), datahackers_sel, sum)tree<-treemap(datahackers_sel,
index=c(variaveis$val[1:3],"Faixa.salarial"),
vSize="count",
type="index",
palette = "Set2",
bg.labels=c("white"),
align.labels=list(
c("center", "center"),
c("right", "bottom")
)
)Como mostrado na tabela acima, serão consideradas as variáveis Tempo de experiência, Cargo e Área de atuação.
d3tree2(tree, rootname = "Todos" )