Música | É possível aplicar Ciência de Dados?

É um desafio encontrar uma área que não possa ser melhorada pela Ciência de Dados.
Um fator que ajuda muito nisso é o aumento exponencial da capacidade de medir e gerar dados, seja qual for a área.
Confesso a vocês que, até parar pra fazer esse artigo, nunca tinha imaginado haver tantos dados sobre músicas, álbuns e bandas.
No caso desse post, isso só foi viável pela excelente API que o Spotify possui. Ela fornece uma quantidade muito interessante de informações sobre cada música, album ou artista.
O que também facilitou muito o trabalho foi a biblioteca spotifyR. Uma verdadeira mão na roda para acessar os dados da API do Spotify pelo R.
Quanto mais subjetiva for a matéria de estudo, maior será a dificuldade de aplicar modelos estatísticos, por exemplo.
A música está dentro de um ramo artístico, portanto, um pouco longe das ciências exatas.
E, ainda assim, é possível aplicar Ciência de Dados! E com muito sucesso.
O Spotify possui sistemas de recomendação muito apurados em seu aplicativo. Então, com base no que você escuta, ele consegue te recomendar músicas e artistas que sejam alinhados com o seu gosto.
Imagino que uma parte desse modelo de recomendação seja composto pelos atributos que eles tem para cada música.
Que atributos são esses?
Para cada música o Spotify atribui valores entre 0 e 100 para vários atributos. Vou listar alguns:
- Acústica
- Dançabilidade
- Sonoridade
- Energia
- Discurso
- Instrumentalidade
- Ao vivo
- Positividade
Ainda que se tenha algumas aplicações práticas muito interessantes da Ciência de Dados na música, não obtive sucesso em todas as minhas tentativas.
Foi muito interessante perceber em gráficos quais as músicas mais tristes ou alegres de uma banda ou ver o modelo do Spotify rodando e nos ajudando a descobrir artistas que combinam muito com nosso gosto musical.
Porém, na minha extremamente breve tentativa de tentar achar um modelo para prever quais seriam as músicas de sucesso de uma banda, os resultados não foram tão satisfatórios.
A minha análise usando os dados do Spotify
Fiz uma enquete lá no Instagram perguntando para o pessoal quais bandas gostariam que eu fizesse uma análise mais detalhada.
As vencedoras foram: Queen, U2, Pink Floyd e Red Hot Chili Peppers.
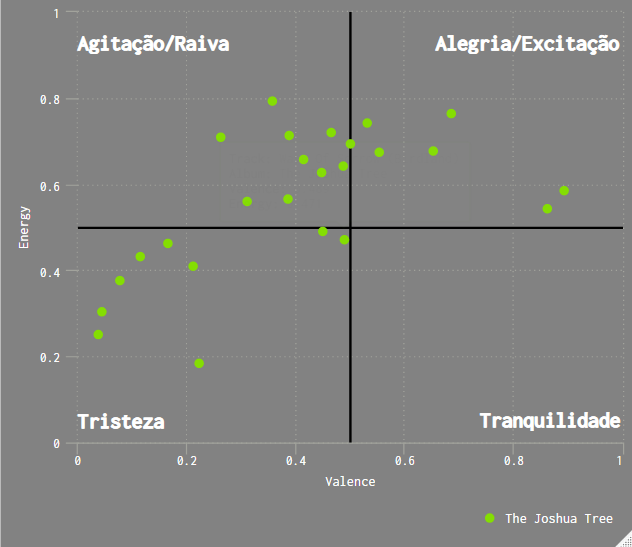
Peguei os valores da positividade e energia das músicas de cada uma dessas 4 bandas e montei o gráfico abaixo. Inclui apenas as músicas do álbum principal de cada uma das bandas.
Apesar das bandas não terem estilos musicais muito distantes, é possível notar padrões nos quadrantes criados.
Dividi o gráfico com as classificações: Tristeza, Agitação/raiva, Alegria/Excitação e Tranquilidade.
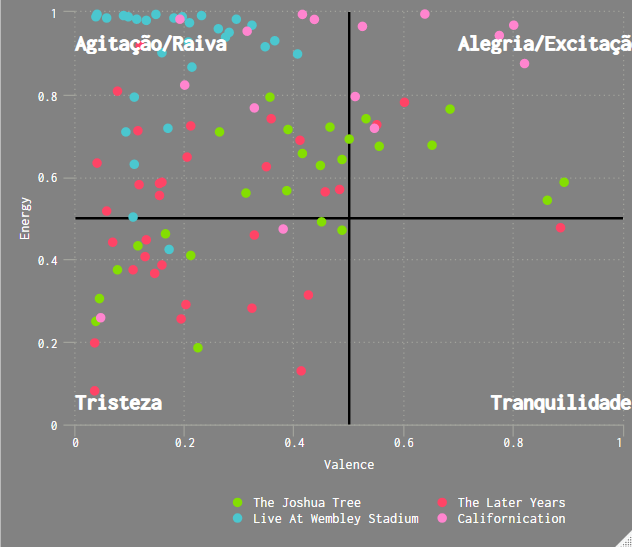
Cada ponto do gráfico é uma canção do álbum. Os álbuns escolhidos foram:
- U2, The Joshua Tree
- Queen, Live At Wembley Stadium
- Pink Floyd, The Later Years
- Red Hot Chili Peppers, Californication
Código e mais análises
Agora vou compartilhar outras análises que fiz e o código utilizado.
Passo 1 - Instalar/Chamar bibliotecas e autenticação
library(tidyverse)
library(spotifyr)
library(genius)
library(tidytext)
library(gridExtra)
library(wordcloud2)
library(dplyr)
library(ggplot2)
library(highcharter)
library(RColorBrewer)
library(randomForest)# Você precisa criar as suas credenciais no Spotify e colocá-las aqui:
Sys.setenv(SPOTIFY_CLIENT_ID = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXX')
Sys.setenv(SPOTIFY_CLIENT_SECRET = 'XXXXXXXXXXXXXXXXXXXXXXXXXX')
# Para criar o seu acesso a API de desenvolvedor do Spotify, siga os passos em:
# https://developer.spotify.com/dashboard/loginBuscar o token de autenticação
access_token <- get_spotify_access_token()Buscar e limpar os dados
Essa função busca no Spotify as principais informações de todas as músicas da banda que você escolher.
No caso, escolhi o U2.
banda <- get_artist_audio_features('u2') ### Buscar os dados# Forças as algumas variáveis a serem da Classe de Fatores
banda$mode_name <- as.factor(banda$mode_name)
banda$key_name <- as.factor(banda$key_name)
banda$key_mode <- as.factor(banda$key_mode)
banda$album_name <- as.factor(banda$album_name)
banda$album_name <- as.factor(banda$album_name)
# tirar musicas repetidas
banda<-banda[!duplicated(banda$track_name),]
# tirar albuns repetidos
banda<-dedupe_album_names(banda, album_name_col = "album_name",
album_release_year_col = "album_release_year")Principais músicas e álbuns
Agora, busquei no Spotify quais são as músicas de mais sucesso da banda. Eles retornam as 10 músicas mais ouvidas.
# buscar músicas de maior sucesso no mercado Americano
top_tracks<-get_artist_top_tracks(id=banda$artist_id[1], market = "US",
authorization = get_spotify_access_token(),
include_meta_info = TRUE)$tracks
# criar uma coluna na tabela informando se a música é top track ou não.
banda <- banda %>%
mutate(topsongs = ifelse(tolower(substr(banda$track_name, start = 1, stop = 11)) %in%
tolower(substr(top_tracks$name, start = 1, stop = 11)), 1,0))
banda$topsongs <- as.factor(banda$topsongs)Definindo quais são os principais albuns da banda.
# Defini que os os principais albuns são aqueles que tem alguma música de sucesso
main_albuns<-banda %>% filter(topsongs==1) %>%
select(album_name)
banda_albums <- banda[banda$album_name %in% main_albuns$album_name,]
banda <- banda %>%
mutate(topalbum = ifelse(album_name %in% main_albuns$album_name , 1,0))
banda$topalbum <- as.factor(banda$topalbum)Visualização de dados
Vamos começar a nossa visualização de dados analisando o sentimento das letras cantadas.
Busquei as 20 palavras mais cantadas no album e separamos as palavras em positivas e negativas.
Mas você concorda que palavras negativas podem ter intensidades muito diferentes?
Por exemplo, a palavra cortar é entendida como uma palavra negativa. Porém, sua intensidade é muito menor do que a de outras palavras negativas como veneno ou fogo.
Então, além de separar as palavras em positivas e negativas, vamos dar um score para cada sentimento.
main_albuns$album_name<-as.character(main_albuns$album_name)
indicador<-names(which.max(table(main_albuns$album_name))[1])
banda_1 <- banda %>%
filter(album_name == indicador)
banda_1 <- banda_1[order(banda_1$tempo),] #sort
banda_1$track_name <- factor(banda_1$track_name, levels = unique(banda_1$track_name))
#Creating a variable called D1 which contains all of the lyrics from Drake's album "Thank Me Later"
D1 <- genius_album(artist = banda$artist_name[1], album = banda_1$album_name[1])
#Using the piping operator to create a count of the most popular words in the album
D1 %>%
unnest_tokens(word, lyric) %>%
anti_join(stop_words) %>%
count(word, sort = TRUE) -> D1Count
#Using more piping operators to create afinn sentiment as well as create a subset of the data that includes the top 20 most popular words
D1Count %>%
inner_join(get_sentiments("afinn")) -> D1Sentiment
D1Sentiment %>% head(20) -> D1Sentiment2
#Creating a column called color that uses an if else statment to color the sentiment score by red if it is below 0 and green if it is above
D1Sentiment2$color <- ifelse(D1Sentiment2$value < 0, "red", "green")
#Creating a bar graph that shows each sentiment. The "color=color" in the ggplot() and scale_color_identity() are what allow the graph to color by red and green based off of the ifelse statement.
sentimento1 <- ggplot(D1Sentiment2, aes(reorder(word, -n), value, color=color)) + geom_col(fill="white") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
labs(title=paste0(banda$artist_name[1]," - ",banda_1$album_name[1]), x="20 palavras mais cantadas", y="Score do sentimento") +
theme(plot.title = element_text(size=15,hjust = 0.5)) +
scale_color_identity()
sentimento1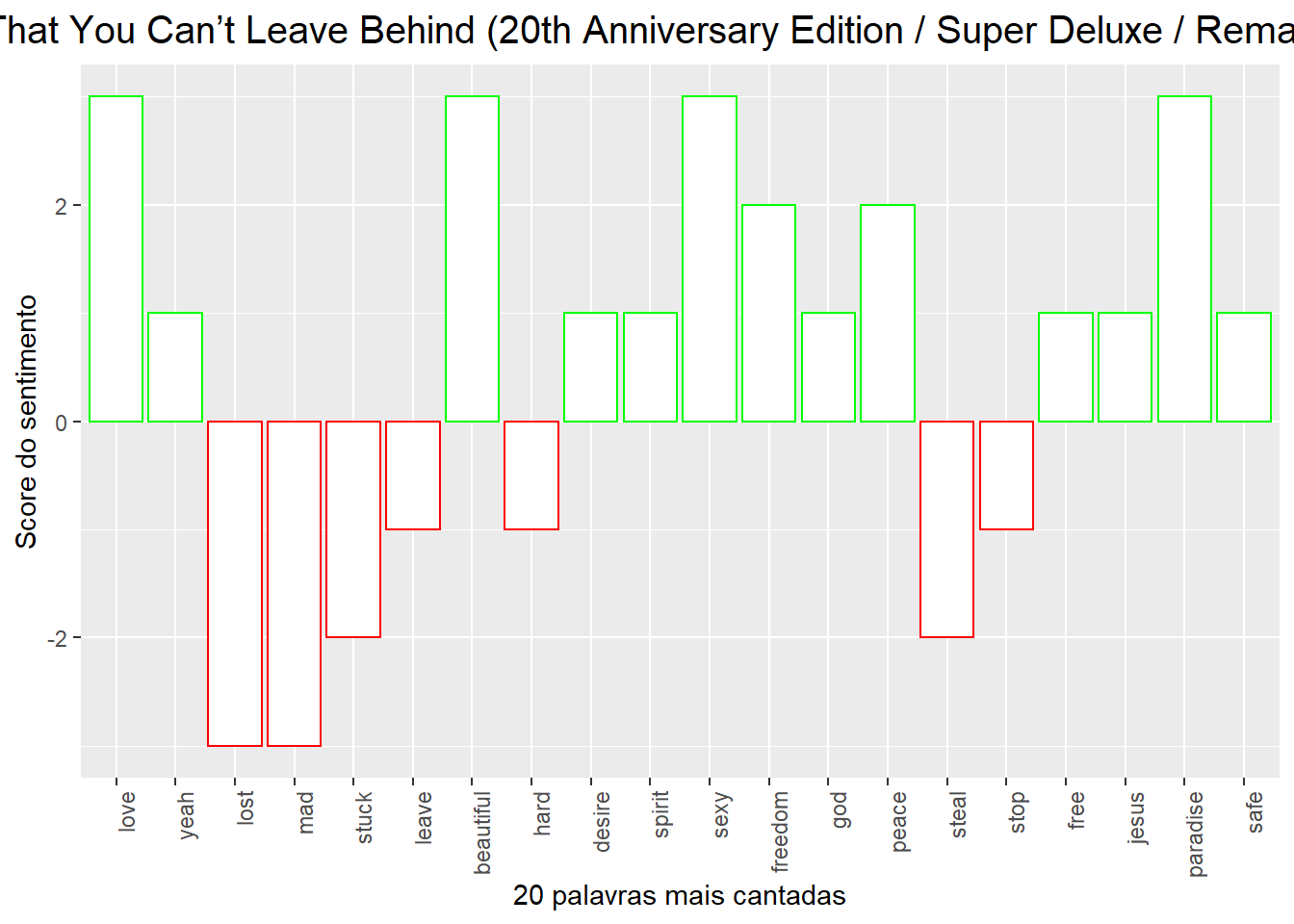
As nuvens de palavras ou wordclouds são uma ótima ferramenta para visualizar quais palavras são mais frequentes.
wordcloud2(data = D1Count)Por fim, coloquei em um gráfico os valores de energia e positividade de cada música do principal album da banda.
artist_quadrant_chart(banda_1) %>%
hc_add_event_point(event = 'mouseOver')