Análise de Sentimentos - Descubra o que estão falando da sua empresa

Você sabe o que é análise de sentimentos e porque ela é INDISPENSÁVEL para uma marca?
Análise de sentimentos é uma técnica para identificar se as opiniões sobre determinado assunto estão sendo positivas ou negativas.
Esse “assunto” pode ser o discurso de um político, um jogador de futebol, uma celebridade, a sua empresa ou o produto que ela acabou de lançar.
Imagine que a sua empresa lançou um produto novo no mercado… Provavelmente vão querer saber o que as pessoas estão falando sobre ele e se a repercussão foi boa ou ruim.
A análise de sentimentos ganhou muita importância por dois fatores:
- Crescimento gigantesco das redes sociais nos últimos anos.
- Necessidade das empresas em acompanharem de forma automatizada o que seus clientes falam sobre ela.
No caso de uma empresa, todos os feedbacks serão de extrema importância para ajustar um produto que foi lançado. Nada será mais rápido e honesto do que o resultado nas redes sociais.
Em questão de segundos, os usuários que já estarão com o celular na mão, irão voluntariamente expor suas opiniões nas redes sociais.
Além disso, não há muito constrangimento. A internet nos permite sair de uma live sem pedir licença ou falar o que não gostamos sem ficar inibido porque a pessoa envolvida está em nossa frente.
O que quero dizer é: o feedback das redes sociais será mais rápido e sincero do que em uma pesquisa presencial, por exemplo. Na pesquisa há uma grande tendência da pessoa amenizar o feedback simplesmente pelo fato de ter uma pessoa na frente e ninguém desejar parecer deselegante.
Então, imagine a importancia para uma empresa saber o que estão falando de seus produtos e de seus posicionamentos. É uma consultoria gratuita que está disponível para as empresas nas redes sociais, com várias sugesões e feedbacks.
O que estão falando da sua empresa ou do seu artista favorito?
O principal objetivo aqui do Blog é colocar a mão na massa e, principalmente, te mostrar como fazer isso.
Escolhi analisar os dados do Twitter. Sabe porque?
Nenhuma outra rede social tem tantas pessoas dando opinião sobre os acontecimentos como no próprio Twitter.
No final desse post coloquei o passo-a-passo que usei e qual foi o raciocínio usado na ferramenta de análise de sentimentos desenvolvida para esse post.
Clique aqui para ir direto ao raciocínio utilizado.
Vamos divertir um pouco aqui pesquisando sobre O SEU TEMA DE INTERESSE.
PASSO 1 - ACESSO A API DO TWITTER
O tem uma ferramenta para facilitar a busca das informações que fazemos na plataforma deles, o que torna a tarefa mais fácil e rápida.
Caso você queira criar a sua própria busca, praticando no seu computador, terá que se cadastrar no Twitter como um desenvolvedor. É bem fácil e leva poucos minutos.
Aqui nesse endereço você tem todas as instruções: https://cran.r-project.org/web/packages/rtweet/vignettes/auth.html
library(rtweet)
#substitua os 4 valores seguintes pelos valores correspondentes ao seu login
# api_key <- "XXXXXXXXX"
# api_secret_key <- "XXXXXXXXX"
# access_token <- "XXXXXXXXX"
# access_token_secret <- "XXXXXXXXX"
## authenticate via web browser
token <- create_token(
app = "analisedesentimento_luisotavio",
consumer_key = api_key,
consumer_secret = api_secret_key,
access_token = access_token,
access_secret = access_token_secret)PASSO 2 - FAZER A BUSCA DESEJADA NO TWITTER
#vamos buscar os últimos 1000 tweets com a palavra "globo" e sem incluir os retweets
input<-"globo"
busca_twitter <- search_tweets(input,n = 1000, include_rts = F)PASSO 3 - LIMPAR O TEXTO ENCONTRADO
library(magrittr)
library(dplyr)
busca_twitter %<>% select(screen_name,text,source) #Selecionar colunas
#remover links
busca_twitter$texto_limpo<-gsub("http\\S+","",busca_twitter$text)
busca_twitter$texto_limpo <- gsub('@([a-z|A-Z|0-9|_])*', '', busca_twitter$texto_limpo) # remove palavras com @ (menções)
busca_twitter$texto_limpo <- gsub('_', ' ', busca_twitter$texto_limpo) # troca underline por espaço
# remove pontuação
busca_twitter$texto_limpo = gsub('[[:punct:]]', ' ', busca_twitter$texto_limpo)
# remove espaços desnecessários
busca_twitter$texto_limpo = gsub('[ \t]{2,}', ' ', busca_twitter$texto_limpo)
busca_twitter$texto_limpo = gsub('^\\s+|\\s+$', ' ', busca_twitter$texto_limpo)
# remove emojis e caracteres especiais
busca_twitter$texto_limpo = gsub('<.*>', ' ', enc2native(busca_twitter$texto_limpo))
# remove quebra de linha
busca_twitter$texto_limpo = gsub('\\n', ' ', busca_twitter$texto_limpo)
# coloca tudo em minúsculo
busca_twitter$texto_limpo = tolower(busca_twitter$texto_limpo)
# remove tweets duplicados
busca_twitter <- busca_twitter[!duplicated(busca_twitter$texto_limpo),]PASSO 4 - CARREGAR AS BASES DE DADOS QUE DEFINEM SE A PALAVRA É POSITIVA OU NEGATIVA
library(lexiconPT)
data("oplexicon_v3.0")
data("sentiLex_lem_PT02")
op30 <- oplexicon_v3.0
sent <- sentiLex_lem_PT02
names(op30)[1]<-"word"
names(sent)[1]<-"word"PASSO 5 - MANIPULAÇÃO DE DADOS
library(tidytext)
library(tm)
busca_twitter %<>% mutate(tweet_id = row_number()) #Cria um id para cada Tweet
# Criar uma linha para cada palavra de um tweet
tweets.input_stem<-busca_twitter %>% select(texto_limpo,tweet_id) %>% unnest_tokens(word,texto_limpo)
#remover stopwords
stop_words_pt<-data.frame(word=(stopwords(kind = "pt")))
stop_words_pt$word<-as.character(stop_words_pt$word)
tweets.input_stem <- tweets.input_stem %>% anti_join(stop_words_pt)
#remover palavras com duas letras
tweets.input_stem %<>% filter(sapply(tweets.input_stem$word,nchar)>2)PASSO 6 - CORRELAÇÃO ENTRE AS PALAVRAS - Quais são as palavras que geralmente aparecem juntas?
library(widyr)
library(igraph)
library(ggraph)
correlacao <- tweets.input_stem %>%
group_by(word) %>%
filter(n() > 40) %>%
pairwise_cor(word, tweet_id, sort = TRUE)
correlacao %>%
arrange(-correlation) %>%
top_n(4) %>% #FILTRANDO APENAS QUANDO A CORRELAÇÃO É MAIOR QUE 0,10 - ESCOLHA SEU CRITÉRIO
graph_from_data_frame() %>%
ggraph(layout = 'fr') +
guides(edge_alpha = "none", edge_width = "none") +
scale_edge_colour_gradientn(limits = c(-1, 1), colors = c("firebrick2", "dodgerblue2")) +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = 'lightblue', size = 5) +
geom_node_text(aes(label = name), repel = TRUE) +
theme_graph() +
labs(title = "Palavras que geralmente apareceram juntas") 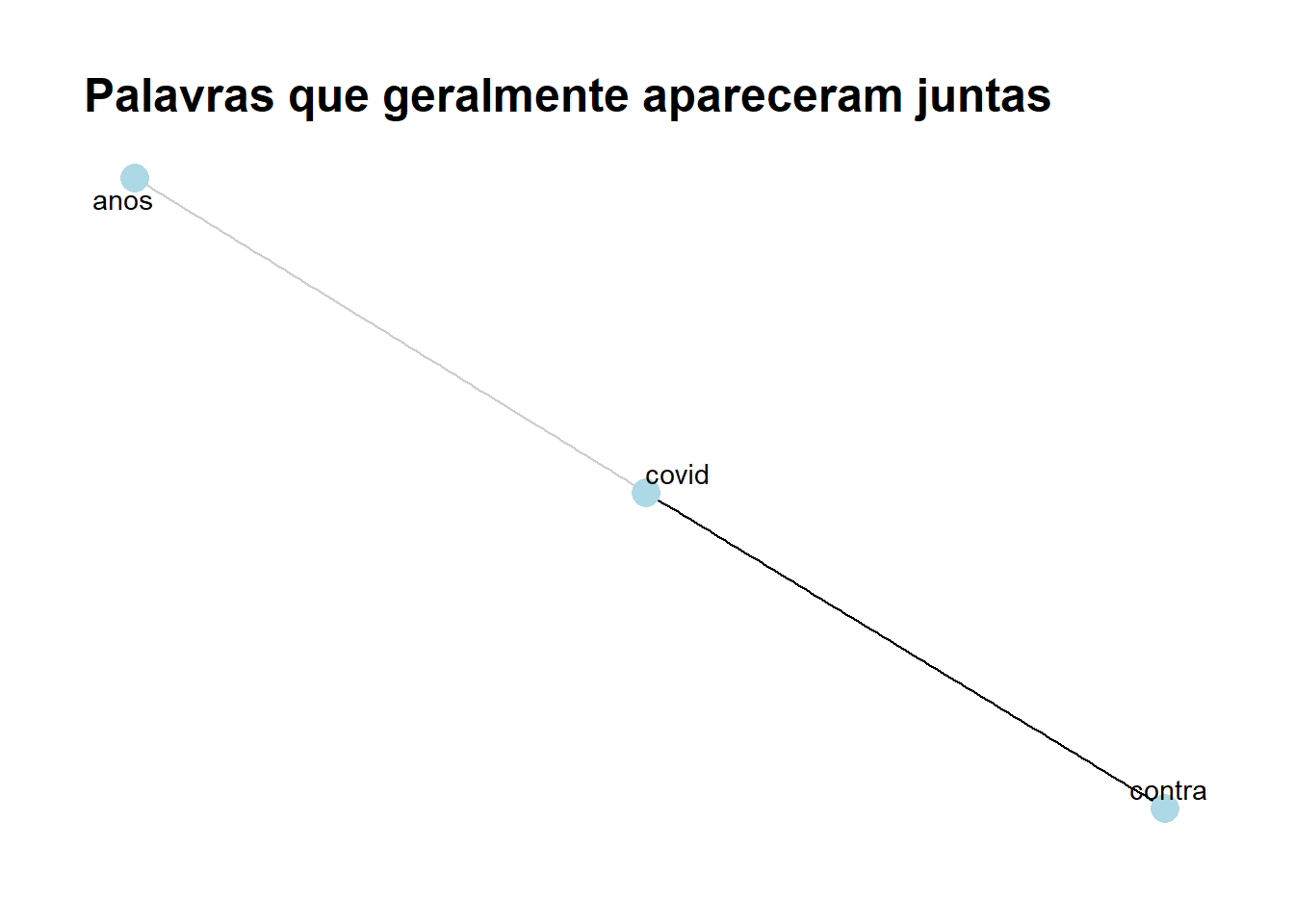
PASSO 7 - TOP 5 - PALAVRAS RELACIONADAS QUE MAIS APARECEM
tweets.input_stem %>% count(word, sort = T) %>% top_n(5) %>%
mutate(word = reorder(word,n)) %>%
ggplot(aes(x = word, y=n)) +
geom_col() +
xlab(NULL) +
coord_flip() +
theme_classic() +
labs(x = "",
y = "Qnt. aparições",
title = paste0("Palavras que aparecem nos tweets com a palavra ",input,"."))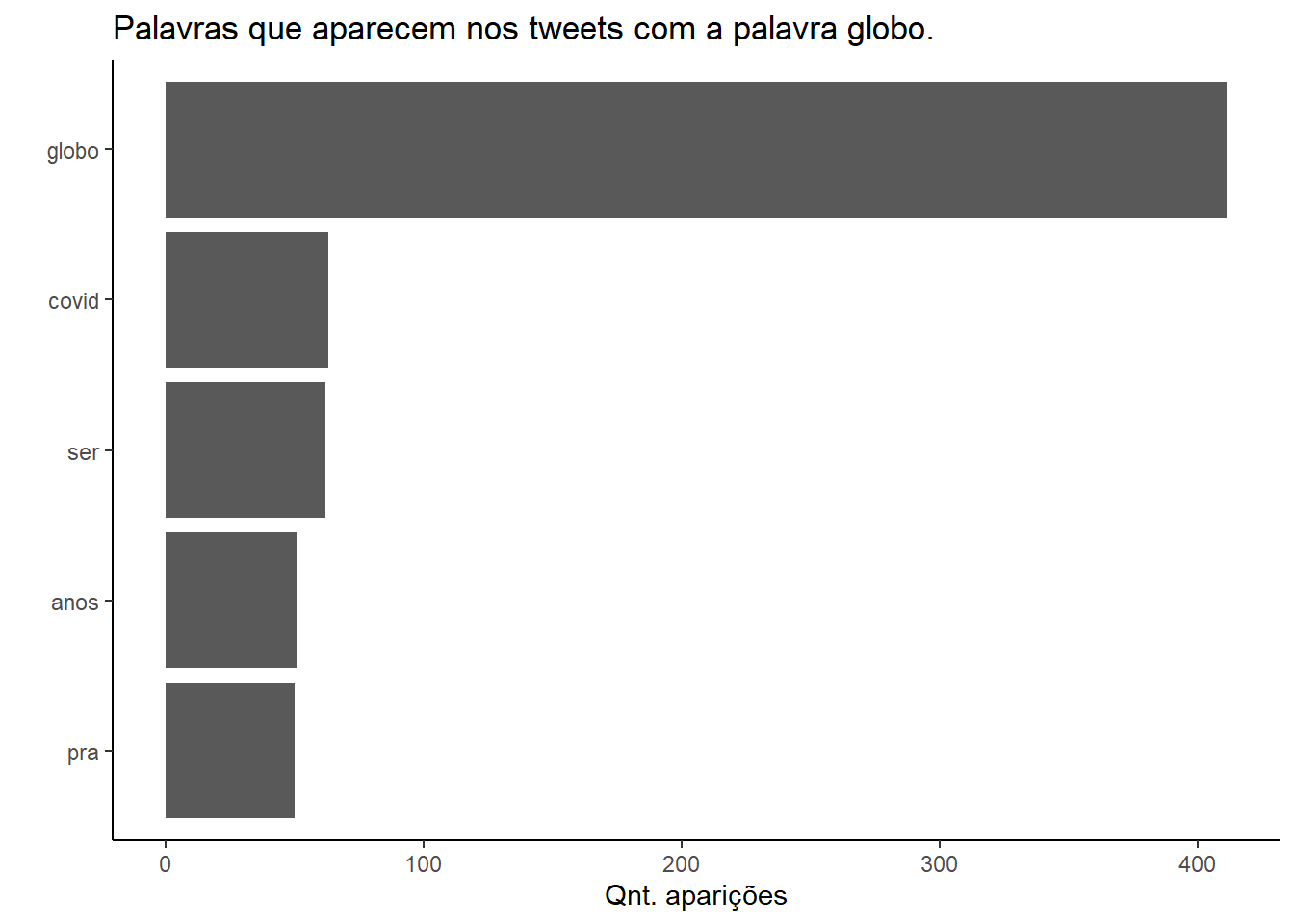
PASSO 8 - SEPARANDO AS PALAVRAS EM SENTIMENTOS POSITIVOS E NEGATIVOS
sentimentos<-tweets.input_stem %>%
inner_join(op30, by = "word") %>%
inner_join(sent %>% select(word, lex_polarity = polarity), by = "word") %>%
group_by(word) %>%
summarise(
tweet_sentiment_op = sum(polarity),
tweet_sentiment_lex = sum(lex_polarity),
n_words = n()
)
sentimentos%<>%filter(tweet_sentiment_op!=0)
sentimentos$sentimento<-ifelse(sentimentos$tweet_sentiment_op>0,"positivo","negativo")
sentimentos %<>% select(word,sentimento,n_words)
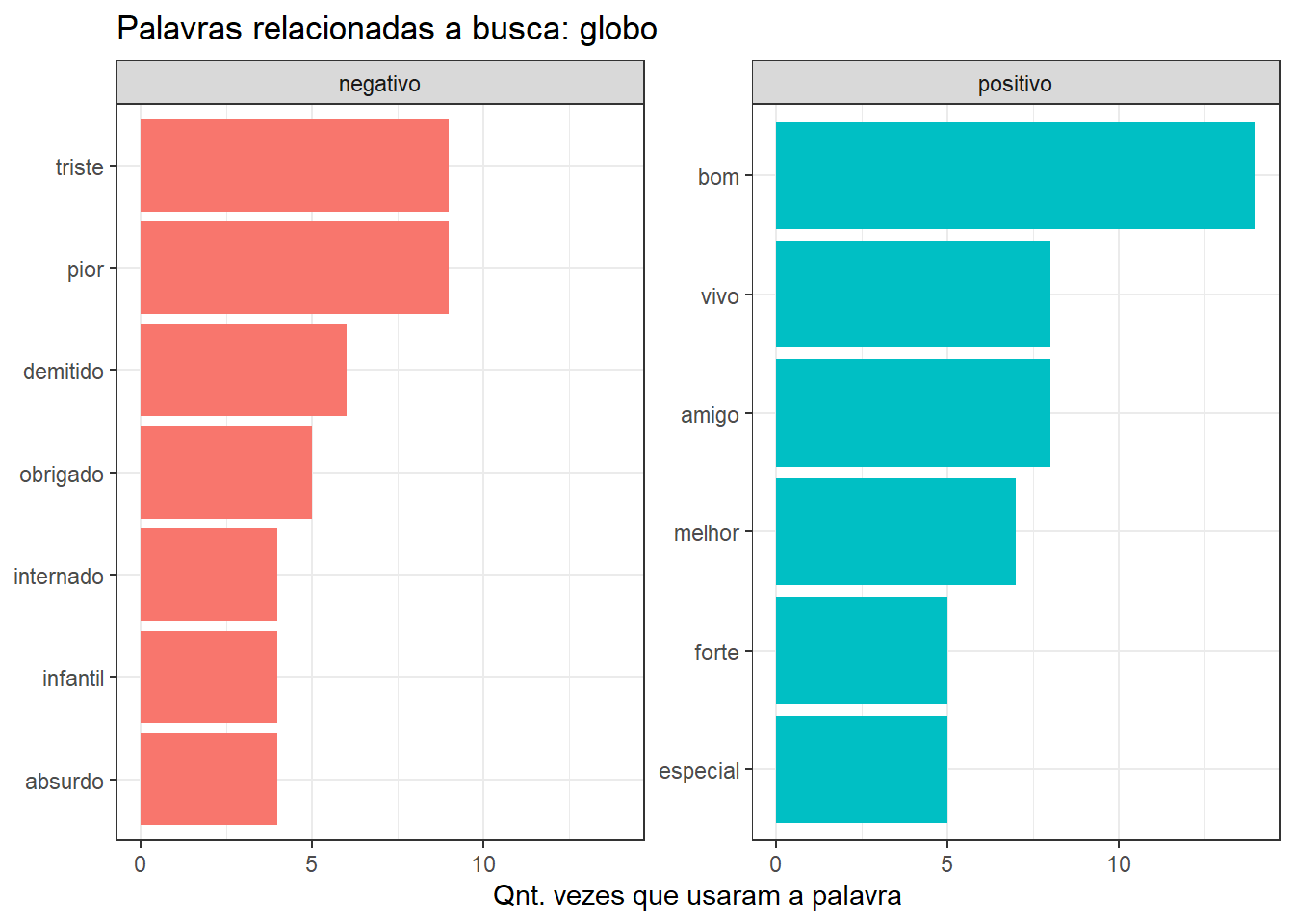
sentimentos %>% group_by(sentimento) %>%
top_n(5) %>%
ungroup() %>%
mutate(word = reorder(word,n_words)) %>%
ggplot(aes(word,n_words,fill=sentimento))+
geom_col(show.legend = FALSE) +
facet_wrap(~sentimento,scales ="free_y") +
labs(title= paste0("Palavras relacionadas a busca: ",input),
y = "Qnt. vezes que usaram a palavra",
x = NULL) +
coord_flip() + theme_bw()